Consensus Diversity Plots Version 2 (CDPs-V.2)
What are they for?
This tool will help you to compare and clasify data sets using diversity metrics (i.e. scaffold counts, fingerprints similarity, molecular properties), describe how diverse each data set is and determine which one is the most diverse.
What are their advantages?
Users are free to calculate and use the metrics they consider to be the most appropriate or the metrics that fit better their objectives.
We are saving the users the pain of having to analyze each metric separately and helping them to avoid the sketchy results obtained after comparing all data sets using only one diversity metric!
The users can compare data sets with different size.
Which metrics could you use and what do they mean?
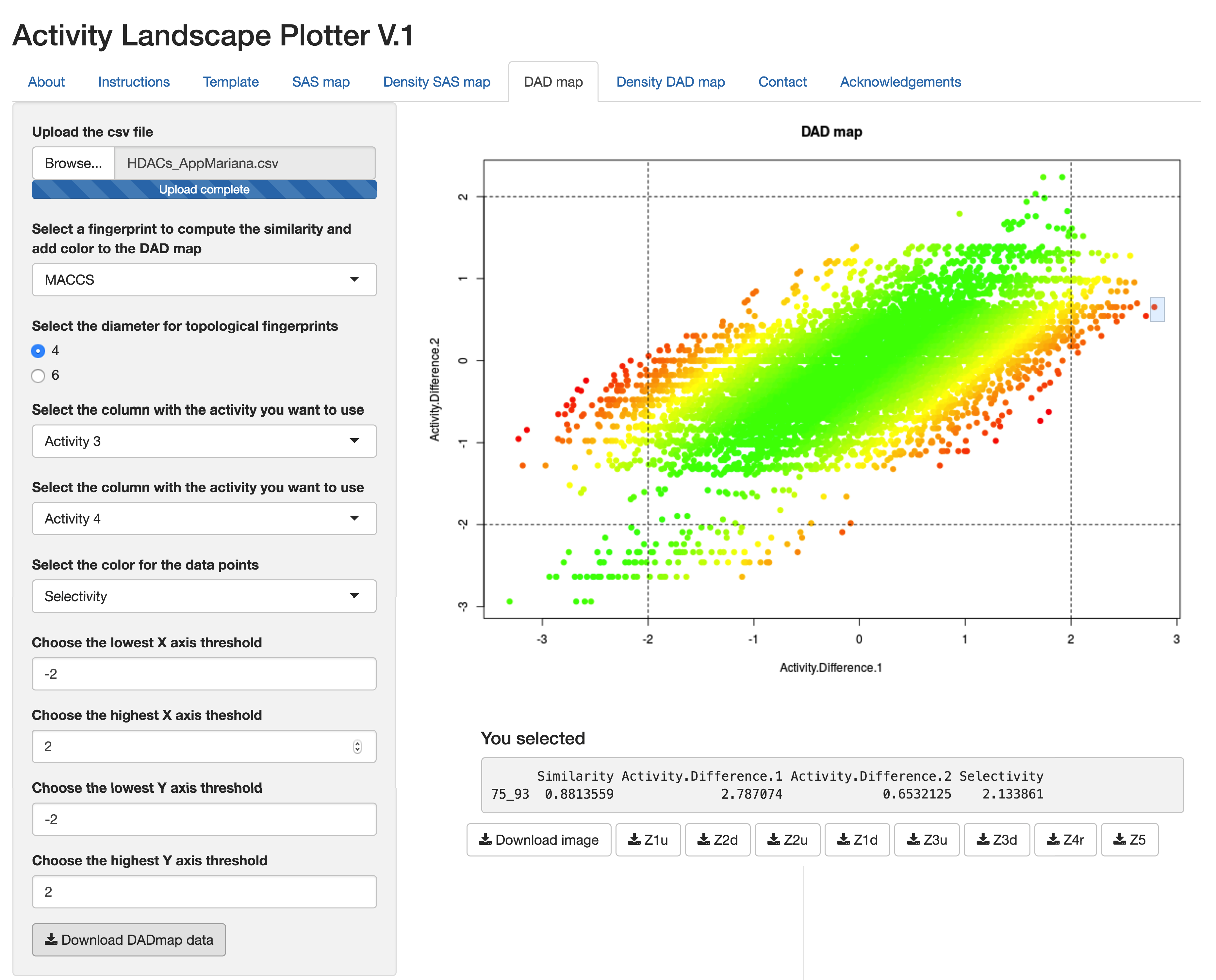
On these plots you are going to visualize the global diversity of your data sets, this means you will visualize how diverse your data sets are comparing their diversity as measured by scaffold content with their diversity depending on how similar the entire structures of the compounds in your data sets are. In addition, you can visualize how diverse your data sets are if you compare their molecular properties.
About the axis:
For the y axis you can choose between four metrics to measure the scaffold or chemotype diversity:
1. Fraction of chemotypes (Chem/NumComp). This fraction is the number of scaffolds or chemotypes in your data set divided by the number of compounds in your data set. The highest value you could get is one and that would be the case only if each compound in your data set has a different scaffold, therefore values closer to one indicate high scaffold diversity. Reference
2. Area under the curve (AUC). This value comes from the CSR curves you make with the fraction of scaffolds or chemotypes plotted on the x axis and the fraction of compounds that contain those scaffolds on the y axis. The highest value you could get is 1, this value corresponds to a curve, meaning that all your compounds share the same scaffold (i.e. low diversity). The lowest value you could get for AUC is 0.5, this indicates you have a straight line and each of the compounds in your data set have a different scaffold (i.e. high scaffold diversity) Reference
3. F50 or the fraction of scaffolds required to retrieve 50% of the compounds in the corresponding data set. In this case the highest value you could get is 0.5, which means each of the compounds in your data set have a different scaffold. Reference
4. Scaled Shannon Entropy (SSEn) this entropy-based metric takes into account the frequency distribution of the compounds in the n most populated scaffolds or chemotypes. The values of SSE range between 0, where all the compounds are contained in one chemotype, and 1, where each chemotypes contains an equal number of compounds. Therefore, SSE values closer to 1 indicate large diversity within the n most populated chemotypes. Reference
You can define the scaffolds using the method of your preference.On the x axis you can plot the intermolecular diversity of the entire molecules using MACCS keys, Extended-Connectivity or any other fingerprint of your choice, using a representative metric of similarity.
About the thresholds:
The thresholds define 4 quadrants on your plot and each quadrant has a meaning in terms of diversity. Let us say you are using F50 on your y axis and ECFP on your x axis, all the data sets with a F50 close to 0.5 and a similarity value closer to 0 would be considered diverse by their scaffold content and if the entire compounds are analyzed, these data sets will be in the quadrant colored in red, while the opposite case (i.e. low F50 and high similarity) will be in the white quadrant. Data sets with many different scaffolds but high similarity values would be on the yellow quadrant, these data sets contain cyclic systems with few side chains that do not contribute to the structural diversity. On the other hand, data sets with mostly acyclic systems and with low similarity values can be found on the blue quadrant.
To set the thresholds we suggest that you use the mean or median of your data sets values, depending on the metric you are using on each axis. However, you can set the thresholds in the way that better fulfills your diversity requirements.
The size and color of the dot for each data set
The size of the dot depends on the size of the data set it represents, bigger dots correspond to bigger data sets. The color scale of the dots represents the molecular properties diversity, you can determine the intra-data set distances using the molecular properties and then use the mean or the median of these distances to set the color of each data set. Green dots represent data sets with lower molecular properties diversity and red dots represent data sets with higher molecular diversity.
Template
DIFACQUIM tools for Cheminformatics